Reading personality traits from between the lines with IBM Watson
In March I went to a talk by one of my colleagues at the Czech NIMH. He is a computer science major PhD student currently working for the IBM and focusing on games, emotions and cognitive sciences overall. He was giving a talk about IBM platform and how it can be to some extent used to decode human emotions and personality from a text. It sounded intriguing, so I immediately tried to give it a go.
The presenter showed us a webapp to input all the texts and commands in, but I wasn’t able to find it, so I decided to use my dear old R to do the work. Its better in the long run anyway :)
During the presentation I created my account at Bluemix, went through infuriating and confusing setup of user, organisation, location and project to start my first personality analyser.
After creating the account and all that, you need to create a Personality Insights app and get your unique API service credentials.
IMPORTANT You get the first 100 analysis calls per month for free, the rest are 1 USD per 50 calls.
username <- "1xxxXX1x-xXx1-11111-xxxx-111xxxxx111" # your own here
password <- "XX1x1x11XX" # your own here
You need some text to give it, so I went with a text I had laying around in my folder, but you can pass it anything. I just recommend removing html tags, newline chars etc. We only want to anlyse the text.
path <- "example.txt"
TEXT <- readChar(path, file.info(path)$size)
#removing newline characters etc.
TEXT <- gsub("[\r\n\t]", "", TEXT)
Then I wrote a simple httr function to make a POST request to the server. It was slightly more complicated than I first thought, because bluemix changed from v2 to v3 during January 2017. Using v3 now requires parameter version to be passed to the URL, othervise you get 400 ERROR. All is quite well covered in Personality Insight API reference.
library(httr)
call_watson <- function(username, password, text){
return(POST(
url = "https://gateway.watsonplatform.net/personality-insights/api/v3/profile?version=2016-10-20",
authenticate(username, password),
add_headers("Content-Type" = "text/plain", "charset" = "utf-8"),
body = text)
)
}
We can then get the content with simple response <- call_watson(username, password, TEXT). The response is in utf8 encoding, so we need to covert it back to text.
response_text <- intToUtf8(response$content)
response_text
## [1] "{\"id\":\"*UNKNOWN*\",\"source\":\"*UNKNOWN*\",\"word_count\":649,\"processed_lang\":\"en\",\"tree\":{\"id\":\"r\",
\"name\":\"root\",\"children\":[{\"id\":\"personality\",\"name\":\"Big 5\",\"children\":[{\"id\":\"Openness_parent\",
\"name\":\"Openness\",\"category\":\"personality\",\"percentage\":0.9956122175799985,\"children\":[{\"id\":\"Openness\",
\"name\":\"Openness\",\"category\":\"personality\",\"percentage\":0.9956122175799985,\"sampling_error\":0.060647148399999996,
\"children\":[{\"id\":\"Adventurousness\",\"name\":\"Adventurousness\",\"category\":\"personality\",\"percentage\":0.5327229012181444,
\"sampling_error\":0.0513245932}, etc."
Server gives you JSON response, that you can parse with jsonlite package. But when you look at the structure of the data using its prettified format, it is quite nested.
jsonlite::prettify(response_text)
## {
## "id": "*UNKNOWN*",
## "source": "*UNKNOWN*",
## "word_count": 649,
## "processed_lang": "en",
## "tree": {
## "id": "r",
## "name": "root",
## "children": [
## {
## "id": "personality",
## "name": "Big 5",
## "children": [
## {
## "id": "Openness_parent",
## "name": "Openness",
## "category": "personality",
## "percentage": 0.9956122175799985,
## "children": [
## {
## "id": "Openness",
## "name": "Openness",
## "category": "personality",
## "percentage": 0.9956122175799985,
## "sampling_error": 0.060647148399999996,
## "children": [
## {
## "id": "Adventurousness",
## "name": "Adventurousness",
## etc.
Luckily we have slightly more complicated yet in this case useful tidyjson package. They syntax is a bit more convoluted, but its better than dealing with the nested jsons by hand.
I extracted the core values with the following script
library(dplyr)
library(tidyjson)
core_values <- response_text %>% enter_object("tree") %>%
enter_object("children") %>% gather_array %>%
spread_values(type = jstring("id")) %>%
enter_object("children") %>% gather_array %>%
enter_object("children") %>% gather_array %>%
spread_values(subtype = jstring("name"), percentage = jnumber("percentage"))
core_values$percentage = core_values$percentage * 100
From there, you can get the Big5 core values simply by big5 <- core_values[core_values$type == "personality", ]. So now we have Big5 percentiles in a data.frame and we can plot them.
ggplot2::ggplot(big5, aes(subtype, percentage, fill = subtype)) +
geom_bar(stat = "identity") + theme(axis.text.x = element_text(angle = 45, hjust = 1), legend.position = "none") +
xlab("Big five personality trait") + ylab("Percentile")
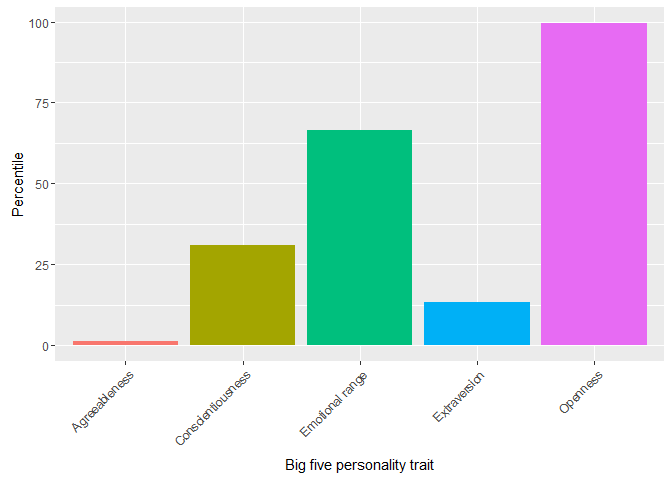
And its as easy as that. In the end I just put all of it into two functions, but it is more instructive to go through it step by step. So give the tranfomration go yourselves!
Entire gist with some extras is here:
Leave a Comment